DeepSeek v3大模型介绍与微软GraphRAG项目介绍
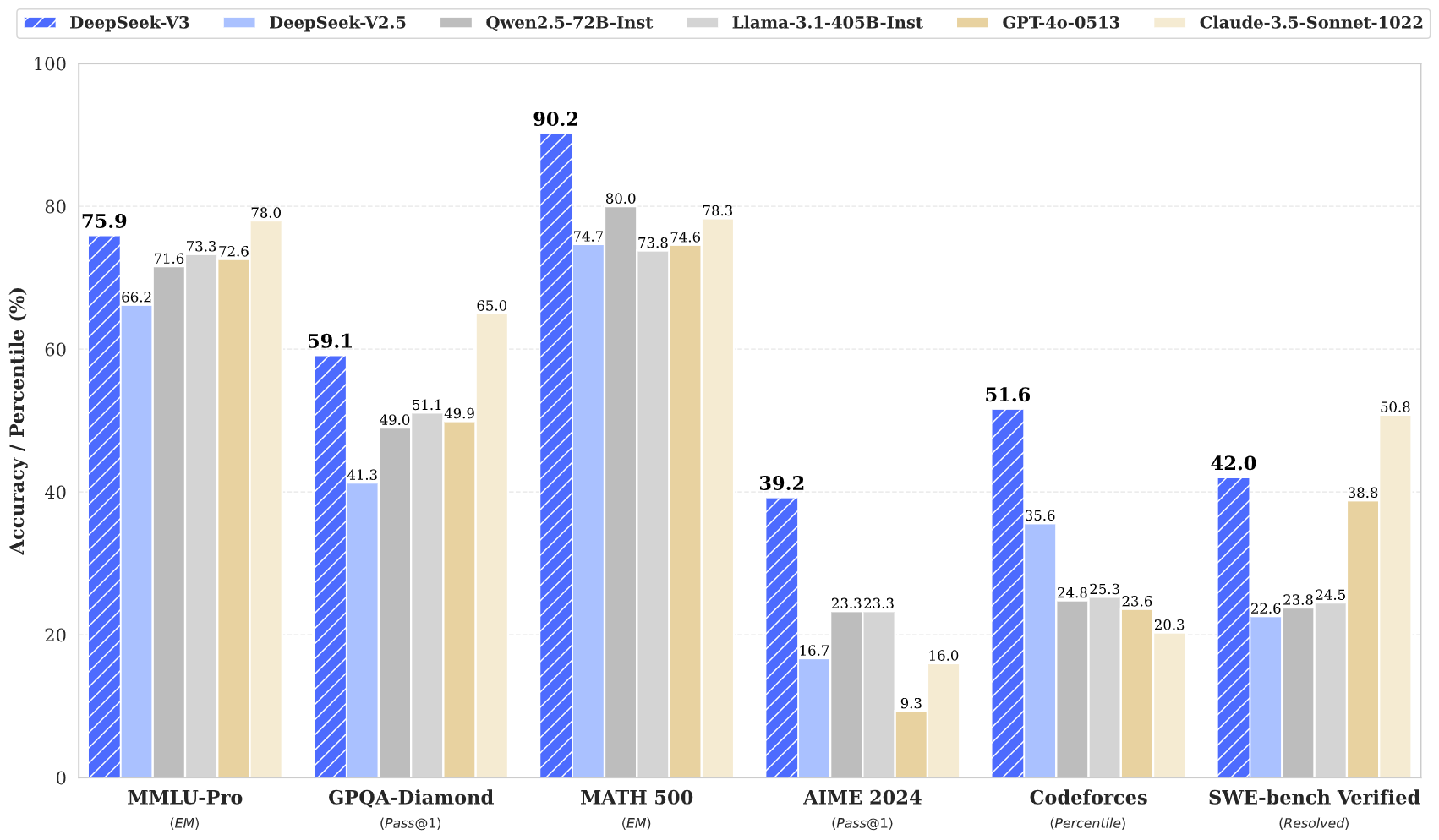
DeepSeek-V3 是由深度求索公司研发的混合专家(MoE)大语言模型,其总参数量达 6710 亿,但每个令牌仅激活 370 亿参数(约占总参数的 5.5%)。这一设计在保证性能的同时显著降低了计算成本。该模型基DeepSeek-V2 架构改进,融合了 多头潜在注意力(MLA) 和 DeepSeekMoE 技术,并通过以下创新进一步提升效率与性能。
传统 MoE 模型依赖辅助损失函数平衡专家负载,而 DeepSeek-V3 首次实现无需辅助损失的负载均衡策略,避免了由此引发的性能下降问题。同时引入多令牌预测目标(MTP),既提升了模型能力,又可结合推测解码技术加速推理。DeepSeek-V3 的预训练消耗 14.8 万亿 tokens 的高质量数据,总训练成本仅 278.8 万 H800 GPU 小时(其中预训练阶段占 266.4 万小时)。其高效性得益于:FP8 混合精度框架:首次验证了 FP8 训练在超大规模模型上的可行性,降低显存与通信开销;算法-框架-硬件协同优化:通过跨节点 MoE 训练的通信瓶颈突破,实现近乎 100% 的计算-通信重叠率,显著提升并行效率。
评测显示,DeepSeek-V3 在多项任务中超越主流开源模型(如 LLaMA、Mixtral),性能接近顶尖闭源模型。值得注意的是,其训练全程未出现不可恢复的损失异常或回滚,稳定性优于多数同规模模型。该模型逼近GPT-4水平,其高效的MoE架构与多Token预测特性,为构建低延迟、高精度的图增强检索(Graph RAG)系统提供了理想的基座模型支持。
GraphRAG: Unlocking LLM discovery on narrative private data

微软研究院推出的GraphRAG通过融合知识图谱与检索增强生成(RAG)技术,革新了传统RAG在复杂查询中的局限性。传统RAG依赖向量搜索匹配语义相似的文本片段,但在需要跨文档关联信息的主题总结或多跳推理任务中,常因检索范围碎片化而失效。GraphRAG的核心突破在于构建结构化知识图谱:在索引阶段,将文本分割为单元后,利用大语言模型(LLM)提取实体、关系及声明,再通过Leiden算法对实体进行层次聚类,生成社区摘要;查询阶段则分为全局搜索(基于社区摘要回答整体性问题)和本地搜索(通过实体邻居关系解析细节)。例如,在分析“Scrooge的人际关系”时,GraphRAG能从图谱中提取其与Marley、Cratchit家族等多层关联,而传统RAG仅能返回孤立片段。
性能对比上,微软基于VIINA数据集(含2023年6月俄乌冲突的数千篇新闻)的实验显示,GraphRAG在复杂场景中显著超越基线模型:当被要求“归纳数据集的五大主题”时,传统RAG因检索偏差输出“城市生活质量”等错误结论,而GraphRAG通过图谱社区摘要(如社区报告513、493)精准识别出“冲突与军事活动”“政治实体”等真实主题;针对多跳推理任务“追踪Novorossiya的破坏行动”,传统RAG因无法关联分散信息而失败,GraphRAG则通过图谱关系链(如关系8335)定位到“PrivatBank ATM爆炸计划”等事件,并整合涉事实体、行动细节及政府反应。评估表明,GraphRAG在答案全面性(覆盖问题所有维度)和多样性(多视角分析)上分别比基线提升40%和35%,且经SelfCheckGPT验证,其事实准确性保持一致。这种差异源于知识图谱赋予LLM的全局语义网络,使碎片化信息得以系统化联结,突破了传统RAG的局部检索瓶颈。
GraphRAG基本原理
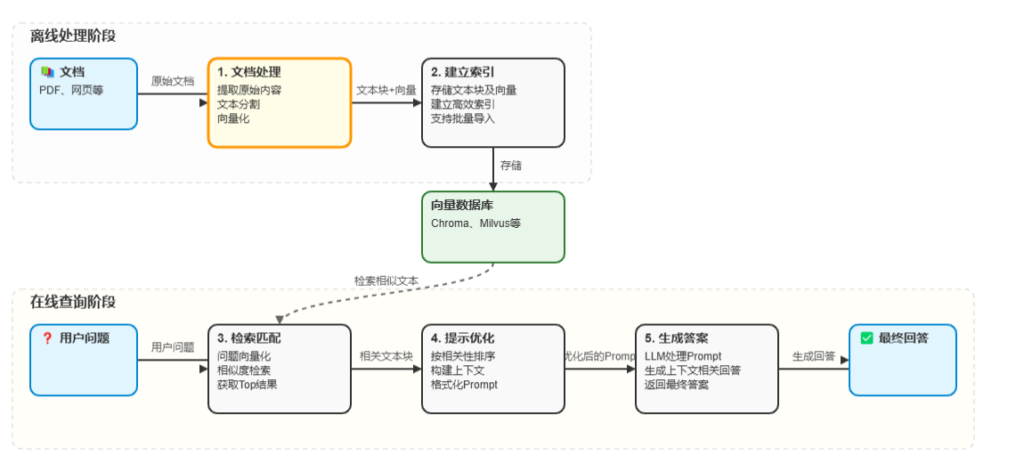
传统的Baseline RAG方法在某些情况下表现不佳,在构建知识库时,通过固定窗口长和重叠切割文本,Text Embeddeding获得向量化存储并保存。当用户向AI提问时,语言模型“翻译”用户问题,并转换为向量,再和数据库中的向量匹配,获得相近文本,作为语言模型的上下文,并回答问题,向量的距离不一定能准确表达文本中实体关系。Graph RAG利用图的思路建立各个节点之间的联系。
基于图的检索,引入了知识图谱来捕捉文本中的实体、关系和其他重要的元书具,从而更有效地进行推理。GraphRAG使用Leiden技术进行层次聚类,将实体及其关系进行组织,提供更丰富的上下文用于解决复杂查询。
GraphRAG运行流程
索引构建:结构化知识图谱生成
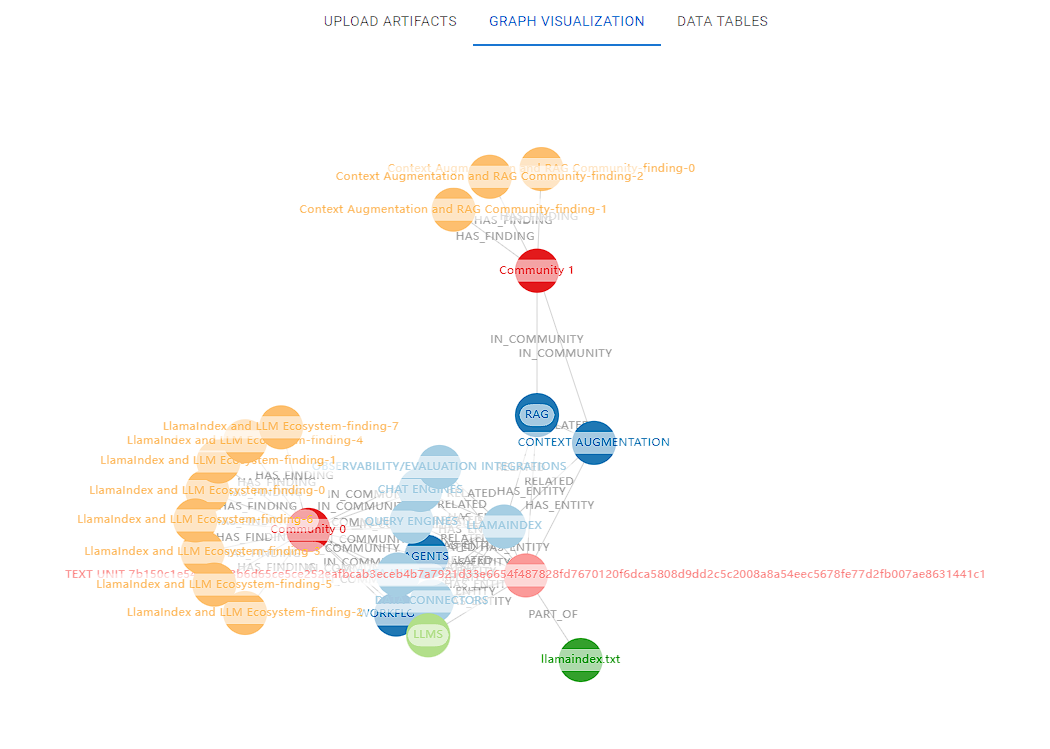
GraphRAG的索引过程采用四步分层策略实现知识结构化。首先将文本切分为可分析的TextUnits单元,利用大语言模型(LLM)精准提取实体、关系及关键声明。基于Leiden算法对实体进行层次聚类构建知识图谱,节点大小和颜色分别映射实体的连接密度与社区归属,形成可视化语义网络。最后通过自底向上的社区总结生成全局语义概览,为数据集提供层级化认知框架,平衡细粒度信息与宏观模式洞察。
查询优化:多模式智能检索体系
GraphRAG提供三种搜索模式适配不同场景需求:全局搜索通过预生成的社区总结快速解析主题宏观趋势;局部搜索聚焦特定实体的直接关联节点输出精准答案;DRIFT搜索创新融合邻居节点与社区上下文,增强复杂问题的推理深度。
Prompt调优
系统特别强调Prompt工程调优,通过优化指令模板提升实体识别、关系抽取和答案生成的准确性,确保检索结果与业务需求高度对齐。
GraphRAG安装和Index-query
基础环境
pip install graphrag初始化环境
graphrag init --root ./graph如果遇到报错,修改配置文件中的encoding_model
### This config file contains required core defaults that must be set, along with a handful of common optional settings.
### For a full list of available settings, see https://microsoft.github.io/graphrag/config/yaml/
### LLM settings ###
## There are a number of settings to tune the threading and token limits for LLM calls - check the docs.
models:
default_chat_model:
type: openai_chat # or azure_openai_chat
api_base: https://dashscope.aliyuncs.com/compatible-mode/v1 #https://api.deepseek.com
....
api_key: ${GRAPHRAG_API_KEY} # set this in the generated .env file
model: deepseek-v3 #deepseek-chats
encoding_model: cl100k_base # automatically set by tiktoken if left undefined
default_embedding_model:
type: openai_embedding # or azure_openai_embedding
api_base: https://dashscope.aliyuncs.com/compatible-mode/v1 #https://<instance>.openai.azure.com
# api_version: 2024-05-01-preview
auth_type: api_key # or azure_managed_identity
api_key: ${TEXT_EMBEDDING_API_KEY}
# audience: "https://cognitiveservices.azure.com/.default"
# organization: <organization_id>
model: text-embedding-v2 #text-embedding-3-small
# deployment_name: <azure_model_deployment_name>
encoding_model: cl100k_base # automatically set by tiktoken if left undefined
...
vector_store:
default_vector_store:
type: lancedb
db_uri: output\lancedb
container_name: default
overwrite: True
embed_text:
model_id: default_embedding_model
vector_store_id: default_vector_store
注意:遇到常见的报错,请使用encoding_model:cl100k_base
执行结果:
上传到如下网站可视化:
https://noworneverev.github.io/graphrag-visualizer
GraphRAG 问答流程
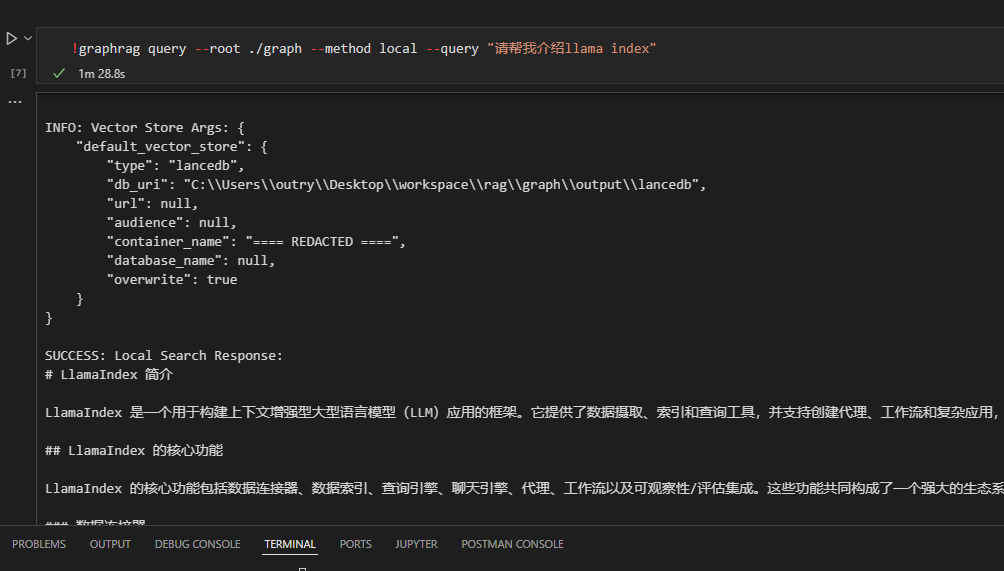
如果希望快速测试问答性能,也可以在命令行中进行快速回答
!graphrag query --root ./graph --method local --query "请帮我介绍llama index"