摘要:本文用最直白的语言,拆解大模型时代最热门的RAG技术,带你理解它如何让AI从“死记硬背”进化到“开卷考试”,解决企业知识落地难题。
一、什么是RAG?——大模型的“外接知识库”
RAG(检索增强生成) 是让大语言模型(LLM)在回答问题时,先通过检索外部知识库获取相关信息,再结合这些信息生成答案的技术。
- 核心逻辑:类似考试时允许查资料,AI先查”课本”再答题。
- 技术组成:
- 检索器:从数据库/文档中筛选相关段落(如用向量相似度匹配)
- 生成器:将检索结果和用户问题结合,生成最终答案(如ChatGPT)
- 与传统大模型的区别:普通大模型依赖训练数据记忆,RAG能动态接入最新知识。
二、为什么需要RAG?——解决大模型的三大痛点
- 知识更新滞后:训练数据截止到2023年的模型,无法回答2025年的新政策。
- 专业领域薄弱:通用模型对医疗、法律等垂直领域细节掌握不足,需接入行业数据库。
- 减少“幻觉”风险:强制模型基于检索结果生成,避免编造不存在的信息。
三、RAG如何工作?——5步拆解技术流程
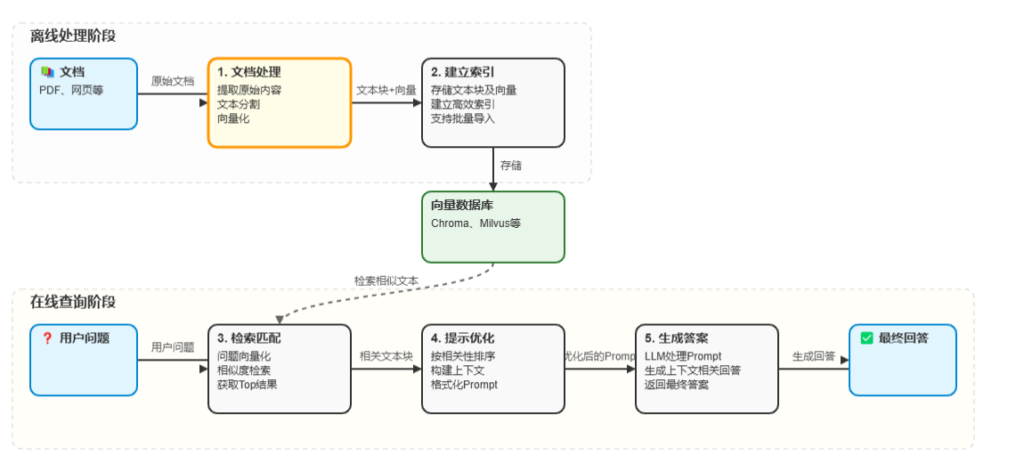
- 文档处理:将PDF、网页等非结构化数据切割为文本块,并生成向量。
- 建立索引:使用向量数据库(如Chroma、Milvus)存储文本到向量数据库中
- 检索匹配:将用户问题转为向量,从库中找出相似度最高的内容。
- 提示优化:将检索结果作为上下文,拼接成Prompt输入大模型。
- 生成答案:模型基于“问题+检索内容”输出最终回答。
四、RAG的典型应用场景
| 场景 | 案例 | 技术价值 |
| 智能客服 | 接入企业产品手册,回答售后问题 | 降低90%人工客服成本 |
| 法律咨询 | 结合最新法律条文生成合规建议 | 避免因法规更新导致错误 |
| 科研助手 | 检索论文库辅助撰写文献综述 | 提升研究效率50% |
| 医疗诊断 | 根据患者症状检索病例库生成初步诊断建议 | 减少漏诊风险 |
五、从零搭建RAG系统:以pdf 为例
步骤0:基础环境安装
在./data 目录下放 pdf文件(DeepSeek:从入门到精通.pdf)
pip install llama-index步骤1:准备数据
- 使用文本分割器,将长文档按语义切分。
- 示例代码:
from llama_index.core import SimpleDirectoryReader
documents = SimpleDirectoryReader("./data").load_data()步骤2:构建索引
- 选择Embedding模型生成向量。
- 使用向量数据库存储。
from llama_index.core import VectorStoreIndex
index = VectorStoreIndex.from_documents(documents)步骤3:检索增强生成
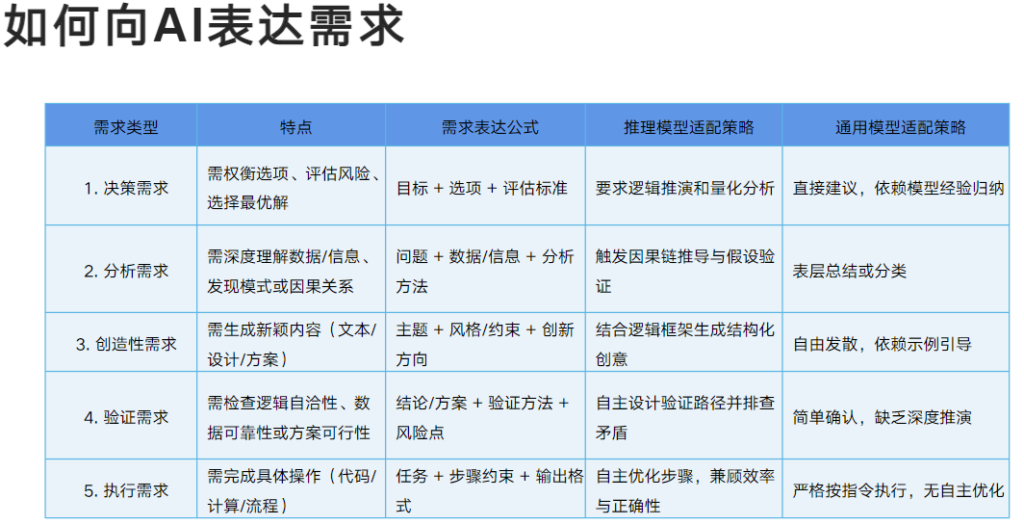
- 将用户问题与数据库匹配:
- 例如文档中有这样一页
from llama_index.core import VectorStoreIndex
index = VectorStoreIndex.from_documents(documents)
query_engine = index.as_query_engine()
response = query_engine.query(
"如何向AI表达需求?"
)
print(response)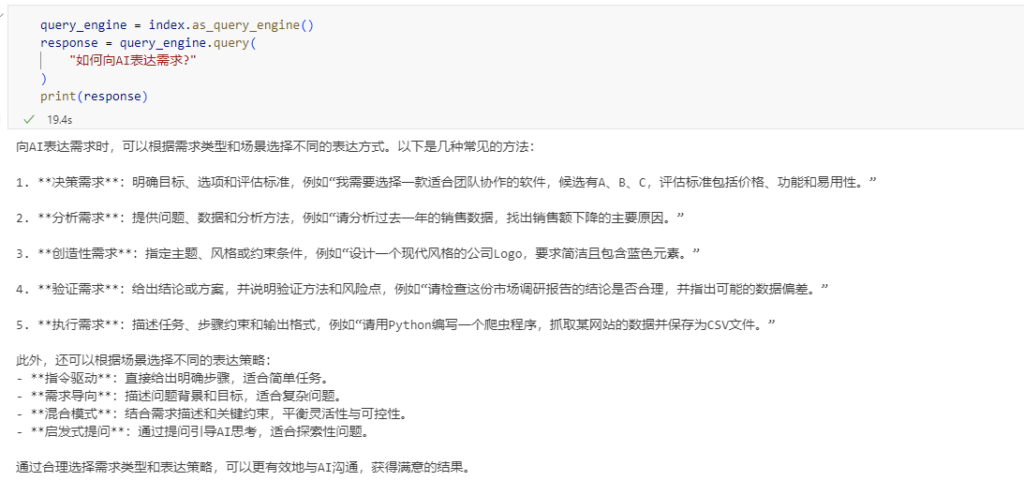
注意:如果遇到网络问题,llama-index 需要重新设置如下步骤:
LLM模型设置
from llama_index.core import Settings
from llama_index.llms.deepseek import DeepSeek
# you can also set DEEPSEEK_API_KEY in your environment variables
# llm = DeepSeek(model="deepseek-reasoner", api_key="you_api_key")
Settings.llm = DeepSeek(
base_url="https://api.deepseek.com/v1",
api_key="sk-xxxx",
model="deepseek-chat",
temperature=0.1)Text Embedding 模型
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader, Settings
from llama_index.embeddings.huggingface import HuggingFaceEmbedding
from llama_index.core import StorageContext
# ----------------------
# 配置嵌入模型为 bge-small-zh
# ----------------------
model_name = "BAAI/bge-small-zh-v1.5"
Settings.embed_model = HuggingFaceEmbedding(
model_name=model_name,
# 如果已下载到本地,可替换为本地路径(如 "./models/bge-small-zh")
#model_name="./models/bge-small-zh",
cache_folder="./embedding_models" # 本地缓存目录
)六、RAG优化技巧和RAG的未来趋势
- 分块策略:避免机械按字数切割,改用语义分割(如句末切分)。
- 混合检索:结合关键词搜索(BM25)与向量检索,兼顾准确性与召回率。
- 重排序(Rerank):用小型模型对检索结果二次打分,排除无关内容。
- 多模态扩展:支持图片、表格检索,适用于医疗影像分析等场景。
- Agent化:让RAG自主判断何时检索、如何迭代查询。
- 知识图谱融合:用图结构关联检索结果,提升推理深度。
- 端到端训练:联合优化检索器与生成器,避免“检索-生成”割裂。